TL;DR: Generating stable RPCs is hard, and I'm not sure how to do it!
RPCs in the context of the geospatial world are equations for describing how a geometrically raw sensor image can be related to a location in the real world. RPC can variously expand to Rational Polynomial Coefficient or Rapid Positioning Coefficients. They consist of 80 coefficents for a ratio of two third degree polynomials (for x and y) plus 10 more values for normalizing image and geographic coordinates.
A couple background papers include one by Vincent Tao and others on Understanding the Rational Function Model (pdf), and one by Gene Dial and J. Grodecki titled RPC Replacement Camera Models (pdf). These date from the mid-2000s, but they reference some earlier work by Gene Dial and J. Grodecki who seem to have played the seminal role in promoting the use of RPCs as generic replacements for rigerous camera models. I believe the major satellite image vendors have now been delivering RPC models (example) for raw scenes for on the order of a decade.
I, and others, have added support to GDAL for reading and representing RPCs as metadata over the a number of years, as well as support for evaluating RPCs in gdalwarp as a way of georeferencing images. At it's very simplest a command like the following can be used to roughly rectify a raw image that has RPCs.
gdalwarp -rpc raw.tif rectified.tif
In fact, at FOSS4G NA this year, a command like this was the big reveal in Paul Morin's discussion of how the Polar Geospatial Center was able to efficiently process huge numbers of satellite scenes of the polar regions. I was rather surprised since I wasn't aware of this capability being in significant use. However the above use example will usually do a relatively poor job. RPCs encapsulate the perspective view of the satellite and as such you need to know the elevation of an early location in order to figure out exactly where it falls on the raw satellite image. If you had a relatively flat image at a known elevation you can specify a fixed elevation like this:
gdalwarp -rpc -to RPC_HEIGHT=257 raw.tif rectified.tif
However, in an area that is not so flat, you really need a reasonably could DEM (digital elevation model) of the region so that distortion effects from terrain can be taken into account. This is particularly important if the view point is relatively low (ie. for an airphoto) or if the image is oblique rather than nadir (straight down). You should be able to do this using a command referencing a DEM file for the area like this, though to be honest I haven't tried it recently (ever?) and I'm not sure how well it works:
gdalwarp -rpc -to RPC_DEM=srtm.tif raw.tif rectified.tif
The above is essentially review from my point of view. But with my recent move from Google to Planet Labs I have also become interested in how to generate RPCs given knowledge of a camera model, and the perspective view from a satellite. This would give us the opportunity to deliver raw satellite scenes with a generic description of the geometry that can already be exploited in a variety of software packages, including GDAL, OSSIM, Orfeo Toolbox and proprietary packages like ArcGIS, Imagine and PCI Geomatica. However, I had no idea how this would be accomplished and while I earned an Honours BMath, I have let the modest amount of math I mastered in the late 80's rot ever since.
So, using what I am good at, I started digging around the web for open source implementations for generating RPCs. Unfortunately, RPC is a very generic term much more frequently used to mean "Remote Procedure Call" in the software development world. Nevertheless, after digging I learned that the Orfeo Toolbox (OTB) has a program for generating RPCs from a set of GCPs (ground control points). Ground control points are just a list of locations on an image where the real world location is known. That is a list of information like (pixel x, pixel y, longitude, latitude, height). That was exciting, and a bit of digging uncovered the fact that in fact Orfeo Toolbox's RPC capability is really just a wrapper for services used from OSSIM. In particular core RPC "solver" is found in the source files ossimRpcSolver.cc, and ossimRpcSolver.h. They appear to have been authored by the very productive Garrett Potts.
Based on the example of the Orfeo Toolbox code, I wrote a gcps2rpc C++ program that called out to libossim to transform GCPs read from a text file into RPCs written to a GDAL VRT file.
For my first attempt I created 49 GCPs in a 7x7 pattern. The elevations were all zero (ie. they were on the WGS84 ellipsoids) and they were generated using custom code mapping from satellite image pixels to ground locations on the ellipsoid. I included simple code in gcps2rpc to do a forward and reverse evaluation of the ground control points to see how well they fit the RPC. In the case of this initial experiment the forward transformation, (long, lat, height) to (pixel, line) worked well with errors in the order of 1/1000th of a pixel. Errors in the inverse transformation, (pixel, line, height) to (long, lat) was less good with worst case errors on the order of 1/10th of a pixel.
At first I wasn't sure what to make of the errors in the inverse direction. 1/10th of a pixel wasn't terrible from my perspective, but it was still a fairly dramatic difference from the tiny errors in the forward direction. I tried comparing the results from evaluating the RPCs with OSSIM and with GDAL. To test with GDAL I just ran gdaltransform something like this.
gdaltransform -rpc -i simulated_rgb.vrt
-85.0495014028 39.7243133317 (entered in terminal)
2016.00011619623 1792.00003975369 0 (output in terminal)
and:
gdaltransform -rpc simulated_rgb.vrt
2016 1792 (entered in terminal)
-85.0495014329239 39.7243132735733 0 (output in terminal)
I found that GDAL and OSSIM agreed well in the forward transform, but while they both had roughly similar sized errors in the inverse they were still fairly distinct results. Reading through the code the reasoning became fairly obvious. They both use iterative solutions for the inverse transform and start with very different initial guesses, and they have fairly weak requirements for covergence. In the case of GDAL the convergence threshold was 1/10th of a pixel. OK, so that leaves me thinking there may be room to improve the inverse functions but accepting that the errors I'm seeing are really all about the iterative convergence.
Next I tried using the RPCs with gdalwarp to actually "rectify" the image. Initially I just left a default elevation of zero for gdalwarp, so I used a command like:
gdalwarp -rpc simulated_rgb.vrt ortho_0.tif
The results seemed plausible but I didn't have a particularly good way to validate it. My test scene is in Indiana, so I used a lat/long to height web service to determine that the region of my scene had a rough elevation of 254m above sea level (we will treat that as the same as the ellipsoid for now). So I tried:
gdalwarp -rpc -to RPC_HEIGHT=254 simulated_rgb.vrt ortho_254.tif
On review of the resulting image, it exactly overlayed the original. I had been hoping the result would have been slightly different based on the elevation. After a moments reflection and a review of the RPC which had many zero values in the terms related to elevation I realized I had't provided sufficient inputs to actually model the perspective transform. I had't given any GCPs at different heights. Also, the example code made it clear that an elevation sensitive RPC could not be generated with less than 80 GCPs (since the equations have 80 unknowns).
My next step was to produce more than 80 GCPs and to ensure that there was more than one elevation represented. It seemed like two layers of 49 GCPs - one at elevation zero, and one at an elevation of 300m should be enough to do the trick, so I updated my GCP generating script to produce an extra set with an ellipsoid that was 300m "bigger". I then ran that through gcps2rpc.
I was pleased to discover that I still got average and maximum errors at the GCPs very similar to the all-zero case. I also confirmed that the GCPs at 300m were actually at a non-trivially different location. So it seemed the RPCs were modelling the perspective view well, at least at the defining positions. I thought I was home free! So I ran a gcpwarp at a height of 0m, 300m and 254m. The results at 0m and 300m looked fine, but somehow the results at 254 meters was radically wrong - greatly inflated! A quick test with gdaltransform gave a sense of what was going wrong:
gdaltransform -rpc simulated_rgb.vrt
0 0 0
-85.036383862713 39.6431112403042 0
0 0 300
-85.0363998100256 39.6431575414329 300
0 0 254
-84.9815303476089 39.2011322215184 254
Essentially this showed that pixel/line location 0,0 was transforming reasonably at the elevations 0 and 300, but at 254 the results were far from the region expected. Clearly the RPCs were not generally modelling the perspective view well. This is the point I am at now. Is it not clear to me what I will need to do to produce stable RPCs for my perspective view from orbit. Perhaps there is a more suitable pattern or number of GCPs to produce. Perhaps the OSSIM RPC generation code needs to be revisited. Perhaps I need to manually construct RPC coefficients that model the perspective view instead of just depending on a least squares best fit to produce reasonable RPCs from a set of GCPs.
Anyways, I hope that this post will provide a bit of background on RPCs to others walking this road, and I hope to have an actually solution to post about in the future.
Sunday, September 8, 2013
Thursday, March 28, 2013
Getting Started with GeoTools
TL;DR: Use Eclipse->Import->Maven to build an eclipse project for GeoTools.
The project I work on at Google (Earth Engine) uses the GeoTools Java library, primarily for coordinate system transformations. We have been using it for a few years for this purpose and it mostly works ok though we have worked around a few quirks. I think it is desirable for our team to be able to contribute at least some small fixes back upstream to GeoTools and so I've been struggling to get to the point where that can be done smoothly.
The next step was internal, where my coworker +Eric Engle, who maintains our internal GeoTool tree, adjusted our use of GeoTools so we build from source and are in a position to patch our local version as we improve things. I had tried to do this once last fall and failed to overcome some challenges related to special requirements of manifest documents for GeoTools. Something to do with finding factories for things like EPSG databases and such.
And now every time I want my geotools clone on github updated I need to issue the following commands locally in my local github clone - basically pulling the changes down to my local repository and then pushing it back up to my own clone:
git fetch upstream
git merge upstream/master
git push origin master
Blech.
I think things would be a bit different if I had write permission on the GeoTools git repository as then I'd be able to make my changes in a branch in it and then send pull requests against that but that would mean lots of branching which I'm also not too fond of.
The default Java on my workstation is a (possibly googlized) OpenJDK 1.7. I get the impression from Jody that GeoTools is targetted at JDK 1.6 and that most folks use the Oracle JDK, not OpenJDK. I was able to able to revert to using OpenJDK 1.6 but was still getting lots of things missing (I wish I had kept better notes on this part). The net result after searching around was that Maven has "profiles" instructing it how to find some classes in different environments that seems to mostly affect the generation of Java docs. After some messing around we found that because my OpenJDK returned "Google Inc." as the vendor something special was needed and Jody was kind enough to incorporate this upstream.
After this change I was able to compile a Maven build of GeoTools successfully, but it took hours and hours for reasons that were never clear and likely somehow Google specific. Today I decided to try this again at home on my fairly stock Ubuntu 10.04 machine. While not exactly fast, it was much faster and I could compile a "mvn install" on an already built tree without testing in a couple minutes. I will note this time I used a downloaded Maven instead of the one provided by Ubuntu, but trying that at work did not seem to help.
The project I work on at Google (Earth Engine) uses the GeoTools Java library, primarily for coordinate system transformations. We have been using it for a few years for this purpose and it mostly works ok though we have worked around a few quirks. I think it is desirable for our team to be able to contribute at least some small fixes back upstream to GeoTools and so I've been struggling to get to the point where that can be done smoothly.
Contribution Agreements
The first challenge was that we needed permission to contribute. Generally this is not a problem as Google is pretty open source friendly, but in order to get the GeoTools corporate contribution agreement signed we needed to clear it with our legal folks. They balked at signing the original agreement which was ... ahem ... hand crafted ... during the GeoTools incubation process. At this point I was prepared to back off on the effort as I didn't want be the guy who raises a stink because his companies legal people were being difficult, as if that should make it the rest of the worlds problems. However, +Jody Garnett was concerned that others might run into similar concerns and pushed through a GeoTools change request adopting a slight variation on the more widely accepted Apache contribution agreement.The next step was internal, where my coworker +Eric Engle, who maintains our internal GeoTool tree, adjusted our use of GeoTools so we build from source and are in a position to patch our local version as we improve things. I had tried to do this once last fall and failed to overcome some challenges related to special requirements of manifest documents for GeoTools. Something to do with finding factories for things like EPSG databases and such.
MapProjection Tolerances
This put things back in my court. I had a small internally reproducable problem with the spherical mercator projection not staying within the error bounds expected by GeoTools at some points on the globe. After some debugging Eclipse I came to the conclusion that:- It is evil that MapProjection.transform() actually uses Java asserts to confirm that point transformation are invertable within a tolerance. This code only triggers when assertions are enabled, and makes it impossible to run code with transformations outside a reasonable realm without triggering this error when assertions are enabled.
- That the default getToleranceForAssertions() result is awfully tight - 1E-5 meters or 1/10th of millimeter!
- For spherical projections it checks orthodromicDistance() which after stepping through the code I determined is very sensitive to rounding error for small distances. Most locations near where I ran into a problem rounded to zero for distance in meters, while the slightly greater distance in radians at the problem point evaluated to something more like one centimeter, exceeding the error threshold.
Well, those are the details, and I hope eventually to prepare a proper GeoTools bug report with a proposed patch. In order to get to that I decided I needed to setup a "regular" GeoTools build that I could run tests against, and use to prepare a patch. The GeoTools manual has great getting started information which I tried to follow.
Git Hate
GeoTools is hosted on github and I have a love/hate relationship with git. Hmm, lets amend that. I have a hate/hate relationship with git. As I somewhat jestingly tell people I haven't yet got a full decade out of subversion yet after learning it in the middle of last decade so I start with a grudge about being forced to learn a new version control technology while the old one continues to work fine from my perspective. But I also find git way more complicated than necessary. Ultimately I determined that I needed to clone geotools on github so I would have a public repository that I could stage changes on and send pull-requests from since I can't issue pull requests for repositories living on my workstations at Google or at home. Then I cloned that repository locally at work and eventually at home. OK, I struggled a bit before concluding that is what was needed but I'm ok with that.
Next I came to the conclusion that there is no easy way from the github interface to refresh my github clone from the official git instance, and I had to setup "upstream" on my workstation clone with the command:
git remote add upstream http://github.com/geotools/geotools.gitAnd now every time I want my geotools clone on github updated I need to issue the following commands locally in my local github clone - basically pulling the changes down to my local repository and then pushing it back up to my own clone:
git fetch upstream
git merge upstream/master
git push origin master
Blech.
I think things would be a bit different if I had write permission on the GeoTools git repository as then I'd be able to make my changes in a branch in it and then send pull requests against that but that would mean lots of branching which I'm also not too fond of.
Maven
GeoTools uses Maven for building. I installed the Maven Ubuntu package and seemed good to go. All I should need to do is "mvn install" in the GeoTools root directory to build.The default Java on my workstation is a (possibly googlized) OpenJDK 1.7. I get the impression from Jody that GeoTools is targetted at JDK 1.6 and that most folks use the Oracle JDK, not OpenJDK. I was able to able to revert to using OpenJDK 1.6 but was still getting lots of things missing (I wish I had kept better notes on this part). The net result after searching around was that Maven has "profiles" instructing it how to find some classes in different environments that seems to mostly affect the generation of Java docs. After some messing around we found that because my OpenJDK returned "Google Inc." as the vendor something special was needed and Jody was kind enough to incorporate this upstream.
After this change I was able to compile a Maven build of GeoTools successfully, but it took hours and hours for reasons that were never clear and likely somehow Google specific. Today I decided to try this again at home on my fairly stock Ubuntu 10.04 machine. While not exactly fast, it was much faster and I could compile a "mvn install" on an already built tree without testing in a couple minutes. I will note this time I used a downloaded Maven instead of the one provided by Ubuntu, but trying that at work did not seem to help.
Eclipse
Next, I wanted to get to the point where I had an Eclipse project I could use to debug and improve GeoTools with. I tried to following the Eclipse Quick Start docs and learned a few things.- Stock Eclipse 3.8 does not seem to include any of the Maven support even though there is apparently some in Eclipse 3.7. I did find downloading and installing the latest Eclipse (Juno - 4.something) did have good Maven support.
- The described process produces a project where you can use GeoTools as jars, and even debug in, but not modify the GeoTools source. This is ok for a use-only GeoTools user but not for someone hoping to fix things or even make temporary modifications during debugging.
I stumbled around quite a bit trying to get past this. What I discovered is that the Eclipse File->Import->Maven->Existing Maven Projects path can be used to setup a project for one or more GeoTools modules. Select the root directory of the GeoTools source tree and Eclipse will walk the pom.xml files (Maven "makefiles) to figure out the dependencies and where the source is. You will need to select which ones to include.
I ran into complaints about lacking Eclipse understanding of git-commit-id-plugin and something about jjtree. I was able to work around this by not including the "cql" module which needed the jjtree stuff, and by hacking out the entire git-commit-id-plugin from the GeoTools root pom.xml file. After that I also restricted myself to selecting the main "library" and I think "ogc" modules.
The result was an Eclipse project in my workspace for each GeoTools module, including the referencing module I was interested in. I was able to go into the src/test tree and run the junit tests fairly easily and all succeeded except three calls to *.class.desiredAssertionStatus() which I commented out. They did not seem terribly relevant.
Conclusion
Well, I can't say that I have accomplished my first meaningful contribution to GeoTools yet, but I have at least gotten to the point where I can build and work on things. Despite some great getting start docs (mostly by Jody I think) and direct support from Jody in IRC (#geotools on freenode) it was still a painful process. This is partly due to my relative lack of familiarity with Maven, Github, and even Eclipse outside of the very narrow way I use it at Google. But it also seems that GeoTools is a big project and there are lots of traps one can fall into with versions of the various tools (Eclipse, Maven, Java runtime, etc). But hopefully people will see that if I can hack it, you likely can too.
Thursday, March 15, 2012
PROJ 4.8.0 Released
Early this week I announced the release of PROJ 4.8.0. It turns out the last release (4.7.0) was in 2009 so it has been quite some time coming.
PROJ.4 is a C library implementation transformations between a wide variety of geospatial coordinate systems. It features include support for many projection methods (ie. Transverse Mercator) as well as support for converting between geodetic datums. As a library it is used by many of the C/C++ open source geospatial applications, and a few proprietary ones including GDAL/OGR, PostGIS, GRASS, MapServer and QGIS (some of my favorites). It also includes commandline utilities mostly used for testing and a dictionary of coordinate system definitions based on the EPSG coordinate system from OGP.
The announcement lists the major new features, but there is a subset I would like to call out here because I think they are quite significant.
I would also be negligent if I failed to call out the important funding support of the US Army Corp of Engineers in these developments via Howard Butler and Liblas / PDAL.
PROJ.4 is a C library implementation transformations between a wide variety of geospatial coordinate systems. It features include support for many projection methods (ie. Transverse Mercator) as well as support for converting between geodetic datums. As a library it is used by many of the C/C++ open source geospatial applications, and a few proprietary ones including GDAL/OGR, PostGIS, GRASS, MapServer and QGIS (some of my favorites). It also includes commandline utilities mostly used for testing and a dictionary of coordinate system definitions based on the EPSG coordinate system from OGP.
The announcement lists the major new features, but there is a subset I would like to call out here because I think they are quite significant.
- A great deal of work went into making the library threadsafe. The main previous hole in threadsafe operation was the use of the global pj_errno for errors. This has been worked around by introduction of an "execution context" object (projCtx) which can be passed in when creating projection objects (projPJ). The execution context also now provides a mechanism to manage error and debug message output. See use of projCtx in proj_api.h for an idea of how this would be used. The execution context also means that more than one part of a process can use PROJ.4 with less risk of stepping on each other (imagine MapServer and GDAL/OGR for instance).
- Preliminary support has been added for vertical datums using the +geoidgrids= directive. The geoidgrids are assumed to provide a transformation from geoid elevations to ellipsoidal elevations and they are discussed a bit in the VerticalDatums topic on the web site.
- I have introduced yet another supported horizontal grid shift file format which I call CTable2. It is really the same as the venerable binary format produced by nad2bin, but with the header regularized and the byte order fixed so that the format is binary compatible across all platforms. This means it is no longer to worry about having distinct copies of the grid shift files for environments like 32bit vs. 64bit linux, or windows vs. linux. I had originally intended to just migrate to using NTv2 but it turns out to take twice as much space because of the presence of rarely used error estimate bands.
- The addition of the +axis= switch to control axis orientation. This makes it possible to handle coordinate systems where "X" is north and "Y" is east as well as various other combinations.
I would also be negligent if I failed to call out the important funding support of the US Army Corp of Engineers in these developments via Howard Butler and Liblas / PDAL.
Saturday, November 5, 2011
FOSS4G Videos
Andrew Ross has announced that all the FOSS4G 2011 and State of the Map videos are now up and available at the FOSSLC web site. Andrew provided the following urls to scan these two categories which gives an extended blurb about each video:
http://www.fosslc.org/drupal/category/event/foss4g2011
http://www.fosslc.org/drupal/category/event/sotm
However I prefer the search mechanism which gives lots more talks per page with just the title.
http://www.fosslc.org/drupal/search/node/foss4g2011
At the risk of being self obsessed I'll highlight two of my talks. I can't seem to find the other two.
I had also really wanted to attend Martin Davis' talk on Spatial Processing Using JEQL but somehow missed it. This weekend I'll review it. There were some other great keynotes and presentations. As you can imagine Paul Ramsey's keynote on Open Source Business Models was informative, amusing and engaging.
The videos were captured by Andrew's team of volunteers, and deployed on the FOSSLC site which includes lots of great videos of talks from other conferences. This has really be a passion of Andrew's for some time and at least in the OSGeo community I don't think the value of it has been fully recognized and exploited. I hope that others will look through the presentation and blog, tweet, +1 and like some that they find the most useful and interesting. Virtual word of mouth is one way to improve the leverage from the work of capturing the videos and the effort to produce the original presentations.
I'd also like to thank Andrew and his helpers Teresa Baldwin, Scott Mitchell, Christine Richard, Alex Trofast, Thanha Ha, "Steve", Paul Deshamps, Assefa Yewondwossen, Nathalie West, Mike Adair and "Ben", many of whom I count as personal friends from the OSGeo Ottawa crowd.
http://www.fosslc.org/drupal/category/event/foss4g2011
http://www.fosslc.org/drupal/category/event/sotm
However I prefer the search mechanism which gives lots more talks per page with just the title.
http://www.fosslc.org/drupal/search/node/foss4g2011
At the risk of being self obsessed I'll highlight two of my talks. I can't seem to find the other two.
I had also really wanted to attend Martin Davis' talk on Spatial Processing Using JEQL but somehow missed it. This weekend I'll review it. There were some other great keynotes and presentations. As you can imagine Paul Ramsey's keynote on Open Source Business Models was informative, amusing and engaging.
The videos were captured by Andrew's team of volunteers, and deployed on the FOSSLC site which includes lots of great videos of talks from other conferences. This has really be a passion of Andrew's for some time and at least in the OSGeo community I don't think the value of it has been fully recognized and exploited. I hope that others will look through the presentation and blog, tweet, +1 and like some that they find the most useful and interesting. Virtual word of mouth is one way to improve the leverage from the work of capturing the videos and the effort to produce the original presentations.
I'd also like to thank Andrew and his helpers Teresa Baldwin, Scott Mitchell, Christine Richard, Alex Trofast, Thanha Ha, "Steve", Paul Deshamps, Assefa Yewondwossen, Nathalie West, Mike Adair and "Ben", many of whom I count as personal friends from the OSGeo Ottawa crowd.
Monday, June 20, 2011
Joining Google
Today I accepted a job with Google as a GIS Data Engineer. I will be based in Mountain View California at head office, and involved in various sorts of geodata processing though I don't really know the details of my responsibilities yet.
I have received occasional email solicitations from Google recruiters in the past, but hadn't really taken them too seriously. I assumed it was a "wide net" search for job candidates and I wasn't looking for regular employment anyways. I was happy enough in my role of independent consultant. It gave me great flexibility and a quite satisfactory income.
Various things conspired to make me contemplate my options. A friend, Phil Vachon, moved to New York City for a fantastic new job. His description of the compensation package made me realize opportunities might exist that I was missing out on. Also, with separation from my wife last year the need to stay in Canada was reduced. So when a Google recruiter contacted me again this spring I took a moment to look over the job description.
The description was for the role of GIS Data Engineer it was a dead on match for my skill set. So, I thought I would at least investigate a bit, and responded. I didn't hear back for many weeks so I assumed I had been winnowed out already or perhaps the position had already been filled. But a few weeks ago I was contacted, and invited to participate in a phone screening interview. That went well, and among other things my knowledge of GIS file formats, and coordinate systems stood me in good stead. So I was invited to California for in person interviews.
That was a grueling day. Five interviews including lots of "write a program to do this on the black board" sorts of questions. Those interviewing me, mostly engineers in the geo group, seemed to know little of my background and I came away feeling somewhat out of place, and like they were really just looking for an entry level engineer. Luckily Michael Weiss-Malik, spent some time at lunch talking about what his group does and gave me a sense of where I would fit in. This made me more comfortable.
Last week I received and offer and it was quite generous. It certainly put my annual consulting income to shame. Also contact with a couple friends inside Google gave me a sense that there were those advocating on my behalf who did know more about my strengths.
I agonized over the weekend and went back and forth quite a bit on the whole prospect. While the financial offer was very good, I didn't particularly need that. And returning to "regular employment" was not inline with my hopes to travel widely, doing my consulting from a variety of exotic locales as long as they had internet access. But, by salting away money it would make it much easier to pursue such a lifestyle at some point in the future.
I also needed to consult extensively with my family. It was very difficult to leave my kids behind, though it helps to know that as teens they are quite independent, I am also confident that their mother would be right there taking good care of them. My kids, and other family members were all very supportive.
My other big concern was giving up my role in the open source geospatial community. While nothing in the job description prevents me from still being active in the GDAL project, and OSGeo, it is clear the job will consume much of my energy and time. I can't expect to play the role I have played in the past, particularly of enabling use of GDAL in commercial contexts by virtual of being available as a paid resource to support users.
I don't have the whole answer to this, but it is certainly my intention to remain active in GDAL/OGR and in OSGeo (on the board and other committees). One big plus of working at Google is the concept of 20% time. I haven't gotten all the details, but it is roughly allowing me to use 20% of my work time for self directed projects. My hope is to use much of my 20% time to work on GDAL/OGR.
Google does make use of GDAL/OGR for some internal data processing and in products like Google Earth Professional. My original hope had been that my job would at least partly be in support of GDAL and possibly other open source technologies within Google. While things are still a bit vague that does not seem to be immediately the case though I'm optimistic such opportunities might arise in the future. But I think this usage does mean that work on GDAL is a reasonable thing to spend 20% time on.
I also made it clear that I still planned to participate in OSGeo events like the FOSS4G conference. I'm pleased to confirm that I will be attending FOSS4G 2011 in Denver as a Google representative and I am confident this will be possible in future years as well.
The coming months will involve many changes for me, and I certainly have a great deal to learn to make myself effective as an employee of Google. But I am optimistic that this will be a job and work place that still allows me to participate in, and contribute to, the community that I love so much. I also think this will be a great opportunity for me to grow. Writing file translators for 20 years can in some ways become a rut!
I have received occasional email solicitations from Google recruiters in the past, but hadn't really taken them too seriously. I assumed it was a "wide net" search for job candidates and I wasn't looking for regular employment anyways. I was happy enough in my role of independent consultant. It gave me great flexibility and a quite satisfactory income.
Various things conspired to make me contemplate my options. A friend, Phil Vachon, moved to New York City for a fantastic new job. His description of the compensation package made me realize opportunities might exist that I was missing out on. Also, with separation from my wife last year the need to stay in Canada was reduced. So when a Google recruiter contacted me again this spring I took a moment to look over the job description.
The description was for the role of GIS Data Engineer it was a dead on match for my skill set. So, I thought I would at least investigate a bit, and responded. I didn't hear back for many weeks so I assumed I had been winnowed out already or perhaps the position had already been filled. But a few weeks ago I was contacted, and invited to participate in a phone screening interview. That went well, and among other things my knowledge of GIS file formats, and coordinate systems stood me in good stead. So I was invited to California for in person interviews.
That was a grueling day. Five interviews including lots of "write a program to do this on the black board" sorts of questions. Those interviewing me, mostly engineers in the geo group, seemed to know little of my background and I came away feeling somewhat out of place, and like they were really just looking for an entry level engineer. Luckily Michael Weiss-Malik, spent some time at lunch talking about what his group does and gave me a sense of where I would fit in. This made me more comfortable.
Last week I received and offer and it was quite generous. It certainly put my annual consulting income to shame. Also contact with a couple friends inside Google gave me a sense that there were those advocating on my behalf who did know more about my strengths.
I agonized over the weekend and went back and forth quite a bit on the whole prospect. While the financial offer was very good, I didn't particularly need that. And returning to "regular employment" was not inline with my hopes to travel widely, doing my consulting from a variety of exotic locales as long as they had internet access. But, by salting away money it would make it much easier to pursue such a lifestyle at some point in the future.
I also needed to consult extensively with my family. It was very difficult to leave my kids behind, though it helps to know that as teens they are quite independent, I am also confident that their mother would be right there taking good care of them. My kids, and other family members were all very supportive.
My other big concern was giving up my role in the open source geospatial community. While nothing in the job description prevents me from still being active in the GDAL project, and OSGeo, it is clear the job will consume much of my energy and time. I can't expect to play the role I have played in the past, particularly of enabling use of GDAL in commercial contexts by virtual of being available as a paid resource to support users.
I don't have the whole answer to this, but it is certainly my intention to remain active in GDAL/OGR and in OSGeo (on the board and other committees). One big plus of working at Google is the concept of 20% time. I haven't gotten all the details, but it is roughly allowing me to use 20% of my work time for self directed projects. My hope is to use much of my 20% time to work on GDAL/OGR.
Google does make use of GDAL/OGR for some internal data processing and in products like Google Earth Professional. My original hope had been that my job would at least partly be in support of GDAL and possibly other open source technologies within Google. While things are still a bit vague that does not seem to be immediately the case though I'm optimistic such opportunities might arise in the future. But I think this usage does mean that work on GDAL is a reasonable thing to spend 20% time on.
I also made it clear that I still planned to participate in OSGeo events like the FOSS4G conference. I'm pleased to confirm that I will be attending FOSS4G 2011 in Denver as a Google representative and I am confident this will be possible in future years as well.
The coming months will involve many changes for me, and I certainly have a great deal to learn to make myself effective as an employee of Google. But I am optimistic that this will be a job and work place that still allows me to participate in, and contribute to, the community that I love so much. I also think this will be a great opportunity for me to grow. Writing file translators for 20 years can in some ways become a rut!
Friday, February 18, 2011
MapServer TIFF Overview Performance
Last week Thomas Bonfort, MapServer polymath contacted me with some surprising performance results he was getting while comparing two ways of handling image overviews with MapServer.
In one case he had a single GeoTIFF file with overviews built by GDAL's gdaladdo utility in a separate .ovr file. Only one MapServer LAYER was used to refer to this image. In the second case he used a distinct TIFF file for each power-of-two overview level, and a distinct LAYER with minscale/maxscale settings for each file. So in the first case it was up to GDAL to select the optimum overview level out of a merged file, while in the second case MapServer decided which overview to use via the layer scale selection logic.
He was seeing performance using the MapServer multi-layer approach being about twice what it was with letting GDAL select the right overview. He prepared a graph and scripts with everything I needed to reproduce his results.
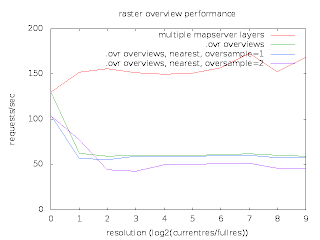
I was able to reproduce similar results at my end, and set to work trying to analyse what was going on. The scripts used apache-bench to run MapServer in it's usual cgi-bin incarnation. This is a typical use case, and in aggregate shows the performance. However, my usual technique for investigating performance bottlenecks is very low-tech. I do a long run demonstrating the issue in gdb, and hit cntl-c frequently, and use "where" to examine what is going on. If the bottleneck is dramatic enough this is usually informative. But I could not apply this to the very very short running cgi-bin processes.
So I set out to establish a similar work load in a single long running MapScript application. In doing so I discovered a few things. First, that there was no way to easily load the OWSRequest parameters from an url except through the QUERY_STRING environment variable. So I extended mapscript/swiginc/owsrequest.i to have a loadParamsFromURL() method. My test script then looked like:
The second thing I learned is that Thomas' recent work to directly use libjpeg and libpng for output in MapServer had not honoured the msIO_ IO redirection mechanism needed for the above. I fixed that too.
This gave me a proces that would run for a while and that I could debug with gdb. A sampling of "what is going on" showed that much of the time was being spent loading TIFF tags from directories - particularly the tile offset and tile size tag values.
The base file used is 130000 x 150000 pixels, and is internally broken up into nearly 900000 256x256 tiles. Any map request would only use a few tiles but the array of pointers to tiles and their sizes for just the base image amounted to approximately 14MB. So in order to get about 100K of imagery out of the files we were also reading at least 14MB of tile index/sizes.
The GDAL overview case was worse than the MapServer overview case because when opening the file GDAL scans through all the overview directories to identify what overviews are available. This means we have to load the tile offset/size values for all the overviews regardless of whether we will use them later. When the offset/size values are read to scan a directory they are subsequently discarded when the next directory is read. So in cases where we need to come back to a particular overview level we still have to reload the offsets and sizes.
For several years I have had some concerns about the efficiency of files with large tile offset/size arrays, and with the cost of jumping back and forth between different overviews with GDAL. This case highlighted the issue. It also suggested an obvious optimization - to avoid loading the tile offset and size values until we actually need them. If we access an image directory (ie overview level) to get general information about it such as the size, but we don't actually need imagery we could completely skip reading the offsets and sizes.
So I set about implementing this in libtiff. It is helpful being a core maintainer of libtiff as well as GDAL and Mapserver. :-) The change was a bit messy, and also it seemed a bit risky due to how libtiff handled directory tags. So I treat the change as as an experimental (default off) build time option controlled by the new libtiff configure option --enable-defer-strile-load.
With the change in place, I now get comparable results using the two different overview strategies. Yipee! Pleased with this result I have commited the changes in libtiff CVS head, and pulled them downstream into the "built in" copy of libtiff in GDAL.
However, it occurs to me that there is still an unfortunate amount of work being done to load the tile offset/size vectors when doing full resolution image accesses for MapServer. A format that computed the tile offset and size instead of storing all the offsets and sizes explicitly might do noticeable better for this use case. In fact, Erdas Imagine (with a .ige spill file) is such a format. Perhaps tonight I can compare to that and contemplate a specialized form of uncompressed TIFF files which doesn't need to store and load the tile offset/sizes.
I would like to thank Thomas Bonfort for identifying this issue, and providing such an easy to use set of scripts to reproduce and demonstrate the problem. I would also like to thank MapGears and USACE for supporting my time on this and other MapServer raster problems.
In one case he had a single GeoTIFF file with overviews built by GDAL's gdaladdo utility in a separate .ovr file. Only one MapServer LAYER was used to refer to this image. In the second case he used a distinct TIFF file for each power-of-two overview level, and a distinct LAYER with minscale/maxscale settings for each file. So in the first case it was up to GDAL to select the optimum overview level out of a merged file, while in the second case MapServer decided which overview to use via the layer scale selection logic.
He was seeing performance using the MapServer multi-layer approach being about twice what it was with letting GDAL select the right overview. He prepared a graph and scripts with everything I needed to reproduce his results.

I was able to reproduce similar results at my end, and set to work trying to analyse what was going on. The scripts used apache-bench to run MapServer in it's usual cgi-bin incarnation. This is a typical use case, and in aggregate shows the performance. However, my usual technique for investigating performance bottlenecks is very low-tech. I do a long run demonstrating the issue in gdb, and hit cntl-c frequently, and use "where" to examine what is going on. If the bottleneck is dramatic enough this is usually informative. But I could not apply this to the very very short running cgi-bin processes.
So I set out to establish a similar work load in a single long running MapScript application. In doing so I discovered a few things. First, that there was no way to easily load the OWSRequest parameters from an url except through the QUERY_STRING environment variable. So I extended mapscript/swiginc/owsrequest.i to have a loadParamsFromURL() method. My test script then looked like:
import mapscript
map = mapscript.mapObj( 'cnes.map')
mapscript.msIO_installStdoutToBuffer()
for i in range(1000):
req = mapscript.OWSRequest()
req.loadParamsFromURL( 'LAYERS=truemarble-gdal&FORMAT=image/jpeg&SERVICE=WMS&VERSION=1.1.1&REQUEST=GetMap&STYLES=&EXCEPTIONS=application/vnd.ogc.se_inimage&SRS=EPSG%3A900913&BBOX=1663269.7343875,1203424.5723063,1673053.6740063,1213208.511925&WIDTH=256&HEIGHT=256')
map.OWSDispatch( req )
The second thing I learned is that Thomas' recent work to directly use libjpeg and libpng for output in MapServer had not honoured the msIO_ IO redirection mechanism needed for the above. I fixed that too.
This gave me a proces that would run for a while and that I could debug with gdb. A sampling of "what is going on" showed that much of the time was being spent loading TIFF tags from directories - particularly the tile offset and tile size tag values.
The base file used is 130000 x 150000 pixels, and is internally broken up into nearly 900000 256x256 tiles. Any map request would only use a few tiles but the array of pointers to tiles and their sizes for just the base image amounted to approximately 14MB. So in order to get about 100K of imagery out of the files we were also reading at least 14MB of tile index/sizes.
The GDAL overview case was worse than the MapServer overview case because when opening the file GDAL scans through all the overview directories to identify what overviews are available. This means we have to load the tile offset/size values for all the overviews regardless of whether we will use them later. When the offset/size values are read to scan a directory they are subsequently discarded when the next directory is read. So in cases where we need to come back to a particular overview level we still have to reload the offsets and sizes.
For several years I have had some concerns about the efficiency of files with large tile offset/size arrays, and with the cost of jumping back and forth between different overviews with GDAL. This case highlighted the issue. It also suggested an obvious optimization - to avoid loading the tile offset and size values until we actually need them. If we access an image directory (ie overview level) to get general information about it such as the size, but we don't actually need imagery we could completely skip reading the offsets and sizes.
So I set about implementing this in libtiff. It is helpful being a core maintainer of libtiff as well as GDAL and Mapserver. :-) The change was a bit messy, and also it seemed a bit risky due to how libtiff handled directory tags. So I treat the change as as an experimental (default off) build time option controlled by the new libtiff configure option --enable-defer-strile-load.
With the change in place, I now get comparable results using the two different overview strategies. Yipee! Pleased with this result I have commited the changes in libtiff CVS head, and pulled them downstream into the "built in" copy of libtiff in GDAL.
However, it occurs to me that there is still an unfortunate amount of work being done to load the tile offset/size vectors when doing full resolution image accesses for MapServer. A format that computed the tile offset and size instead of storing all the offsets and sizes explicitly might do noticeable better for this use case. In fact, Erdas Imagine (with a .ige spill file) is such a format. Perhaps tonight I can compare to that and contemplate a specialized form of uncompressed TIFF files which doesn't need to store and load the tile offset/sizes.
I would like to thank Thomas Bonfort for identifying this issue, and providing such an easy to use set of scripts to reproduce and demonstrate the problem. I would also like to thank MapGears and USACE for supporting my time on this and other MapServer raster problems.
Saturday, December 18, 2010
RPATH, RUNPATH and LD_LIBRARY_PATH
Long time since my last post - my bad.
Recently I have been working on a renewed FWTools for linux - hopefully I'll follow up on that later. Much like in the past FWTools is intended to work across a variety of linux systems (ie. Ubuntu, Redhat, Suse, Gentoo) and to not interfere with the native packing system nor to require special permissions to install.
To that end we try to distribute as many of the required shared libraries as possible, and we use the LD_LIBRARY_PATH environment variable to ensure FWTools finds and uses these shared libraries in preference to any system provided versions which might be incompatible (though often aren't).
In my local testing I was getting frustrated as my shared libraries were not being used. Instead the system versions of things like libsqlite3.so.4 were getting picked up from /usr/lib64 despite my LD_LIBRARY_PATH pointing to a copy distributed with FWTools. I check this with the ldd command which shows what sublibraries an executable or shared library need and which is being picked according to the current policy.
I carefully read the man page for ld.so, which is responsible for loading shared libraries at runtime, and it indicated:
The necessary shared libraries needed by the program are searched for
in the following order
o Using the environment variable LD_LIBRARY_PATH
(LD_AOUT_LIBRARY_PATH for a.out programs). Except if the exe‐
cutable is a setuid/setgid binary, in which case it is ignored.
...
Well, my programs are not setuid/setgid nor are they a.out (very old style of linux binary), so what gives? Due to poor time synchronization on my systems and use of nfs, I noticed that some shared library dates were in the future. I thought perhaps some funky security policy prevented them from being used, but that theory did not pan out. I tried doing it on a local file system incase there were some rule about not trusting shared libraries from remote file systems in some cases. Still no go.
However, googling around the net I found that my local ld.so man page was not very comprehensive. Another ld.so man page gave me a hint, referring to DT_RPATH and DT_RUNPATH attributes being used before LD_LIBRARY_PATH. I was vaguely aware of shared libraries having an "rpath" attribute which could be set at link time and might have some sort of influence on searching. Distribution packaging folks have sometimes bugged me about it, especially back in the old days before libtool was used for GDAL. But I had never really understood it well and it just seemed like unnecessary stuff.
Further digging confirmed that ELF (the modern linux object file format) executables and shared libraries may have an RPATH attribute built right into the file. This is essentially a directory that should be searched first for shared libraries that this executable or shared library depends on. RUNPATH is similar, but is apparently evaluated after LD_LIBRARY_PATH. I got my critical information from this blog post by Trevor King.
My old favorite, the ldd command, does not show the rpath settings though it does honour them. I also use nm to dump the symbols in object files and shared libraries, but it doesn't address special attributes like rpath. Digging around I found the readelf command which can report all sorts of information about a shared library or executable, including the RPATH, and RUNPATH. It also helpfully lists the shared libraries that are needed, something that often gets obscured in ldd by the chaining of dependencies.
The rpath attribute is generally set by libtool when linking shared libraries. GDAL includes a build option to build without libtool, and I contemplated using that which would help alot. But it wouldn't help for other libraries in FWTools that were not directly pulled in by GDAL. My goal with the modern FWTools is to - as much as possible - use standard CentOS/RedHat rpm binaries as the basis for the product. So I don't want to have to rebuild everything from scratch. What I really wanted was a way to suppress use of the rpath, switch it to runpath or remove it entirely. Low and behold, I am not the first with this requirement. There is a command called chrpath that can do any of these "in place" to a binary (see chrpath(1) man page).
This command isn't installed by default on my system, but it was packaged and it works very nicely. I'll preprocess the shared libraries and binaries to strip out rpath so my LD_LIBRARY_PATH magic works smoothly. I had even considered using it to replace the rpath at install time with the path inside the FWTools distribution for libraries. This, unfortunately, does not appear to be possible as it seems chrpath can only replace rpath's with rpaths of the same or a shorter length. In any event, FWTools still depends on cover scripts to set other environment variables so doing this wouldn't have made it practical to avoid my environment setup magic.
I owe a lot to some other blog and mailing list posts turned up by google. This blog entry is partly an attempt to seed the net with helpful answers for others that run into similar problems. I will say it is very annoying that a company decided to name itself "rPath" - it made searching quite a bit harder!
Recently I have been working on a renewed FWTools for linux - hopefully I'll follow up on that later. Much like in the past FWTools is intended to work across a variety of linux systems (ie. Ubuntu, Redhat, Suse, Gentoo) and to not interfere with the native packing system nor to require special permissions to install.
To that end we try to distribute as many of the required shared libraries as possible, and we use the LD_LIBRARY_PATH environment variable to ensure FWTools finds and uses these shared libraries in preference to any system provided versions which might be incompatible (though often aren't).
In my local testing I was getting frustrated as my shared libraries were not being used. Instead the system versions of things like libsqlite3.so.4 were getting picked up from /usr/lib64 despite my LD_LIBRARY_PATH pointing to a copy distributed with FWTools. I check this with the ldd command which shows what sublibraries an executable or shared library need and which is being picked according to the current policy.
I carefully read the man page for ld.so, which is responsible for loading shared libraries at runtime, and it indicated:
The necessary shared libraries needed by the program are searched for
in the following order
o Using the environment variable LD_LIBRARY_PATH
(LD_AOUT_LIBRARY_PATH for a.out programs). Except if the exe‐
cutable is a setuid/setgid binary, in which case it is ignored.
...
Well, my programs are not setuid/setgid nor are they a.out (very old style of linux binary), so what gives? Due to poor time synchronization on my systems and use of nfs, I noticed that some shared library dates were in the future. I thought perhaps some funky security policy prevented them from being used, but that theory did not pan out. I tried doing it on a local file system incase there were some rule about not trusting shared libraries from remote file systems in some cases. Still no go.
However, googling around the net I found that my local ld.so man page was not very comprehensive. Another ld.so man page gave me a hint, referring to DT_RPATH and DT_RUNPATH attributes being used before LD_LIBRARY_PATH. I was vaguely aware of shared libraries having an "rpath" attribute which could be set at link time and might have some sort of influence on searching. Distribution packaging folks have sometimes bugged me about it, especially back in the old days before libtool was used for GDAL. But I had never really understood it well and it just seemed like unnecessary stuff.
Further digging confirmed that ELF (the modern linux object file format) executables and shared libraries may have an RPATH attribute built right into the file. This is essentially a directory that should be searched first for shared libraries that this executable or shared library depends on. RUNPATH is similar, but is apparently evaluated after LD_LIBRARY_PATH. I got my critical information from this blog post by Trevor King.
My old favorite, the ldd command, does not show the rpath settings though it does honour them. I also use nm to dump the symbols in object files and shared libraries, but it doesn't address special attributes like rpath. Digging around I found the readelf command which can report all sorts of information about a shared library or executable, including the RPATH, and RUNPATH. It also helpfully lists the shared libraries that are needed, something that often gets obscured in ldd by the chaining of dependencies.
The rpath attribute is generally set by libtool when linking shared libraries. GDAL includes a build option to build without libtool, and I contemplated using that which would help alot. But it wouldn't help for other libraries in FWTools that were not directly pulled in by GDAL. My goal with the modern FWTools is to - as much as possible - use standard CentOS/RedHat rpm binaries as the basis for the product. So I don't want to have to rebuild everything from scratch. What I really wanted was a way to suppress use of the rpath, switch it to runpath or remove it entirely. Low and behold, I am not the first with this requirement. There is a command called chrpath that can do any of these "in place" to a binary (see chrpath(1) man page).
chrpath -d usr/lib64/libgdal.so
This command isn't installed by default on my system, but it was packaged and it works very nicely. I'll preprocess the shared libraries and binaries to strip out rpath so my LD_LIBRARY_PATH magic works smoothly. I had even considered using it to replace the rpath at install time with the path inside the FWTools distribution for libraries. This, unfortunately, does not appear to be possible as it seems chrpath can only replace rpath's with rpaths of the same or a shorter length. In any event, FWTools still depends on cover scripts to set other environment variables so doing this wouldn't have made it practical to avoid my environment setup magic.
I owe a lot to some other blog and mailing list posts turned up by google. This blog entry is partly an attempt to seed the net with helpful answers for others that run into similar problems. I will say it is very annoying that a company decided to name itself "rPath" - it made searching quite a bit harder!
Subscribe to:
Comments (Atom)